Chi-Square Test med Excel
Chi-Square-testet i Excel är det vanligaste icke-parametriska testet som används för att jämföra två eller flera variabler för slumpmässigt valda data. Det är en typ av test som används för att ta reda på förhållandet mellan två eller flera variabler, detta används i statistik som också kallas Chi-Square P-värde, i excel har vi ingen inbyggd funktion men vi kan använda formler för att utföra chi-kvadrat test i Excel genom att använda den matematiska formeln för Chi-Square Test.
Typer
- Chi-Square test för god passform
- Chi-Square test för oberoende av två variabler.
# 1 - Chi-Square-test för god passform
Den används för att uppfatta närheten till ett urval som passar en befolkning. Symbolen för Chi-Square-testet är (2). Det är summan av alla ( Observerat antal - Förväntat antal) 2 / Förväntat antal.
- Där k-1 frihetsgrader eller DF.
- Där Oi är den observerade frekvensen är k kategori och Ei är den förväntade frekvensen.
Anmärkning: - Passformen hos en statistisk modell avser förståelsen för hur väl samplingsdata passar en uppsättning observationer.
Användningar
- Låntagarnas kreditvärdighet baserat på deras åldersgrupper och personliga lån
- Förhållandet mellan prestationer hos säljare och utbildning som erhållits
- Avkastning på ett enda lager och på lager i en sektor som läkemedel eller bank
- Kategori av tittare och effekterna av en TV-kampanj.
# 2 - Chi-Square test för oberoende av två variabler
Det används för att kontrollera om variablerna är autonoma mot varandra eller inte. Med (r-1) (c-1) frihetsgrader
Där Oi är den observerade frekvensen är r antalet rader, c är antalet kolumner och Ei är den förväntade frekvensen
Obs: - Två slumpmässiga variabler kallas oberoende om sannolikhetsfördelningen för en variabel inte påverkas av den andra.Användningar
Test av oberoende är lämpligt i följande situationer:
- Det finns en kategorisk variabel.
- Det finns två kategoriska variabler, och du måste bestämma förhållandet mellan dem.
- Det finns tvärtabeller och förhållandet mellan två kategoriska variabler måste hittas.
- Det finns icke-kvantifierbara variabler (till exempel svar på frågor som, väljer anställda i olika åldersgrupper olika typer av hälsoplaner?)
Hur gör man Chi-Square-testet i Excel? (med exempel)
Chefen för en restaurang vill hitta sambandet mellan kundnöjdhet och lönerna till de som väntar på bord. I detta kommer vi att sätta upp hypotesen för att testa Chi-Square
- Hon tar ett slumpmässigt urval på 100 kunder som frågar om tjänsten var utmärkt, bra eller dålig.
- Hon kategoriserar sedan lönerna för de människor som väntar som låga, medelstora och höga.
- Antag att signifikansnivån är 0,05. Här betecknar H0 och H1 oberoende och beroende av servicekvaliteten på lönerna för väntande bord.
- H 0 - servicekvaliteten är inte beroende av lönerna för personer som väntar på borden.
- H 1 - servicekvaliteten är beroende av lönerna till personer som väntar på borden.
- Hennes resultat visas i tabellen nedan:
I detta har vi 9 datapunkter, vi har 3 grupper, som alla har olika meddelande om lön, och resultatet ges nedan.

Nu ska vi räkna summan av alla rader och kolumner. Vi kommer att göra detta med hjälp av formeln, dvs SUM. För att summera det utmärkta i den totala kolumnen har vi skrivit = SUM (B4: D4) och sedan tryckt på enter-tangenten.

Detta kommer att ge oss 26 . Vi kommer att utföra detsamma med alla rader och kolumner.

För att beräkna frihetsgraden (DF) använder vi (r-1) (c-1)
DF = (3-1) (3-1) = 2 * 2 = 4
- Det finns tre kategorier av tjänster och 3 kategorier av lön.
- Vi har 27 respondenter med medel lön (nedersta raden, mitten)
- Vi har 51 respondenter med en bra service (sista kolumnen, mitten)
Nu måste vi beräkna de förväntade frekvenserna: -
Förväntade frekvenser kan beräknas med en formel: -
- För att beräkna för det utmärkta kommer vi att använda multiplicera summan av låg med totalt utmärkt dividerat med N.
Antag att vi måste beräkna för första raden och 1: a kolumnen (= B7 * E4 / B9 ) . Detta ger det förväntade antalet kunder som har röstat utmärkt service för lönerna för de personer som väntar så låga, dvs. 8,32 .
- E 11 = - (32 * 26) / 100 = 8,32 , E 12 = 7,02 , E 13 = 10,66
- E 21 = 16,32 , E 22 = 13,77 , E 23 = 20,91
- E 31 = 7,36 , E 32 = 6,21 , E 33 = 9,41
På samma sätt måste vi göra detsamma för alla, och formeln tillämpas i nedanstående diagram.

Vi får tabellen Förväntad frekvens enligt nedan: -

Obs: - Antag att signifikansnivån är 0,05. Här betecknar H0 och H1 oberoende och beroende av servicekvaliteten på lönerna för väntande bord.
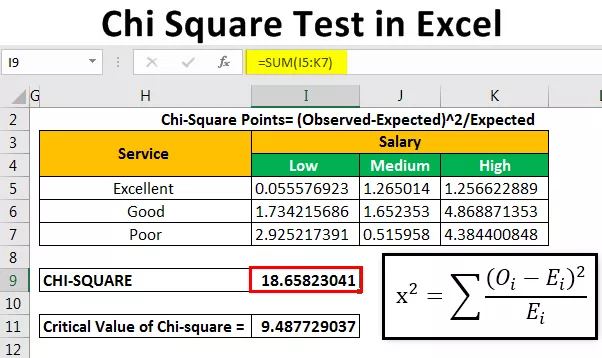
Efter beräkning av den förväntade frekvensen beräknar vi chi-kvadratdatapunkterna med hjälp av en formel.
Chi-Square-poäng = (observerad-förväntad) 2 / förväntad
För att beräkna den första punkten skriver vi = (B4-B14) 2 / B14.

Vi kommer att kopiera och klistra in formeln i andra celler för att fylla värdet automatiskt.

Efter detta beräknar vi chi-värdet (Beräknat värde) genom att lägga till alla värden ovanför tabellen.

Vi fick Chi-värdet som 18.65823 .

För att beräkna det kritiska värdet för detta använder vi en chi-kvadrat kritiskt värdetabell för att vi kan använda formeln nedan.
Denna formel innehåller två parametrar CHISQ.INV.RT (sannolikhet, frihetsgrad).
Sannolikhet är 0,05, och det är ett betydande värde som kommer att hjälpa oss att avgöra om att acceptera nollhypotesen (H 0 ) eller inte.

Det kritiska värdet på chi-kvadrat är 9.487729037.

Nu hittar vi värdet på chi-kvadraten eller (P-värde) = CHITEST (actual_range, förväntad_range)
Område från = CHITEST (B4: D6, B14: D16) .

Som vi har sett är värdet på chi-testet eller P-värdet = 0,00091723.

Vi har beräknat alla värden. De chi-kvadrat (beräknat värde) värden är endast signifikant när dess värde är lika eller mer än det kritiska värdet 9,48, dvs., kritiskt värde (tabellvärdet) måste vara högre än den 18,65 att acceptera nollhypotesen (H 0 ) .
Men här Beräknat värde > Tabulerat värde
X 2 (beräknad)> X 2 (tabulerad)
18,65> 9,48
I detta fall kommer vi att förkasta nollhypotesen (H 0 ), och Alternate (H 1 ) kommer att accepteras.
- Vi kan också använda P-värde för att förutsäga detsamma, dvs om P-värde <= α (signifikant värde 0,05) kommer Null-hypotesen att avvisas.
- Om P-värdet> α , avvisa inte nollhypotesen .
Här P-värde (0,0009172) < α (0,05), avvisa H 0 , acceptera H 1
Från exemplet ovan drar vi slutsatsen att servicekvaliteten är beroende av lönerna för de personer som väntar.
Saker att komma ihåg
- Anser kvadraten för en normal normalvariat.
- Utvärderar om frekvenser observerade i olika kategorier skiljer sig avsevärt från de frekvenser som förväntas under en viss uppsättning antaganden.
- Bestämmer hur väl en antagen distribution passar data.
- Använder beredskapstabeller (i marknadsundersökningar kallas dessa tabeller tvärflikar).
- Den stöder mätningar på nominell nivå.








